TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。即面向流的通信是无消息保护边界的。
TCP 底层并不了解上层业务数据的具体含义,它会根据 TCP 缓冲区的实际情况进行包的划分,所以在业务上认为一个完整的包可能会被 TCP 拆分为多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是 TCP 粘包 和 拆包。
为什么 UDP没有粘包?
粘包拆包问题在数据链路层、网络层以及传输层都有可能发生。日常的网络应用开发大都在传输层进行,由于 UDP 有消息保护边界,不会发生粘包拆包问题,因此粘包拆包问题只发生在 TCP 协议中。
粘包拆包发生场景
因为 TCP 是面向流,没有边界,而操作系统在发送 TCP 数据时,会通过缓冲区来进行优化,例如缓冲区为 1024 个字节大小。
如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP 则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题。
如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP 就会将其拆分为多次发送,这就是拆包。
关于粘包和拆包可以参考下图的几种情况:
正常数据包
正常的理想情况,两个包恰好满足 TCP 缓冲区的大小或达到 TCP 等待时长,分别发送两个包
服务端一共读到两个数据包,第一个包包含客户端发出的第一条消息的完整信息,第二个包包含客户端发出的第二条消息,那这种情况比较好处理,服务器只需要简单的从网络缓冲区去读就好了,第一次读到第一条消息的完整信息,消费完再从网络缓冲区将第二条完整消息读出来消费。这种情况没有发生粘包、拆包。

粘包
两个包较小,间隔时间短,发生粘包,合并成一个包发送
服务端一共就读到一个数据包,这个数据包包含客户端发出的两条消息的完整信息,这个时候服务端不知道如何区分原始的两个包,这种情况其实是发生了 TCP 粘包。

拆包
一个包过大,超过缓存区大小,拆分成两个或多个包发送

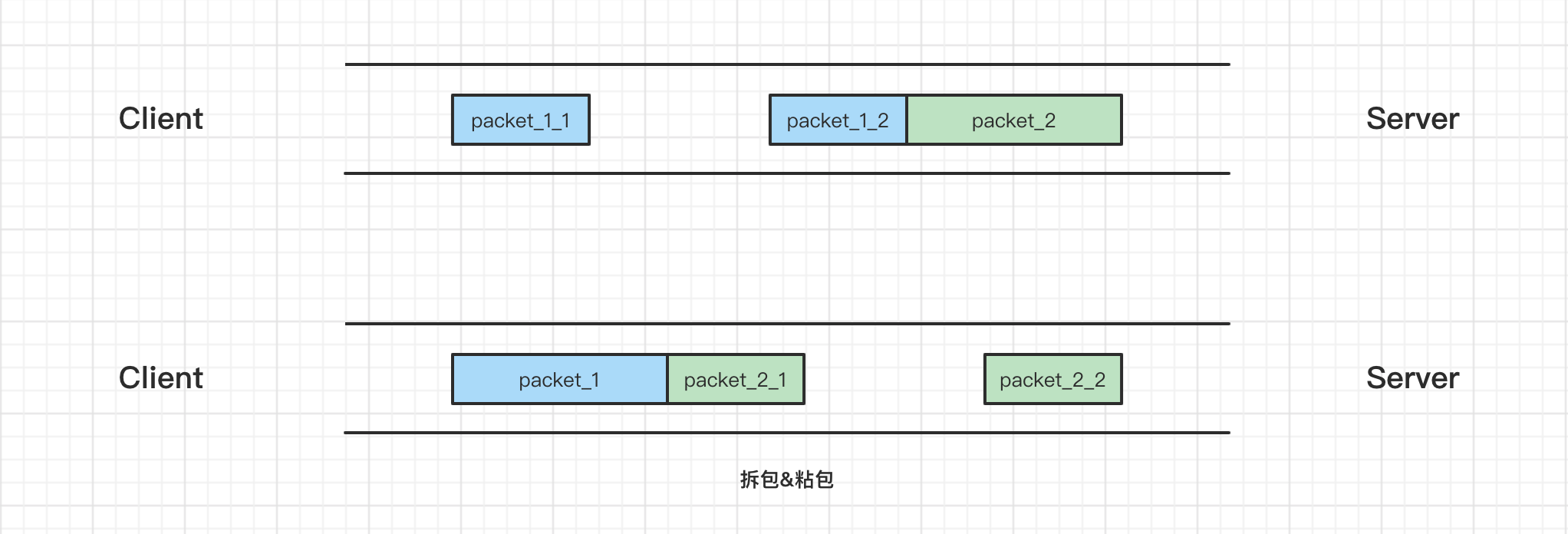
既有粘包又有拆包
packet_1 过大,进行了拆包处理,而拆出去的一部分又与 packet_2 进行粘包处理。
服务端一共收到了两个数据包,第一个数据包只包含了第一条消息的一部分,第一条消息的后半部分和第二条消息都在第二个数据包中,或者是第一个数据包包含了第一条消息的完整信息和第二条消息的一部分信息,第二个数据包包含了第二条消息的剩下部分,这种情况其实是发送了 TCP 拆包,因为发生了一条消息被拆分在两个包里面发送了,同样上面的服务器逻辑对于这种情况是不好处理的。
产生 TCP 粘包和拆包的原因
TCP 是以流的方式传输数据,传输的最小单位为一个报文段(segment)。TCP Header中有个 Options 标识位,常见的标识为 mss(Maximum Segment Size) 指的是,连接层每次传输的数据有个最大限制 MTU(Maximum Transmission Unit),一般是 1500 比特,超过这个量要分成多个报文段,mss 则是这个最大限制减去 TCP 的 header,光是要传输的数据的大小,一般为 1460 比特。换算成字节,也就是 180 多字节。
TCP 为提高性能,发送端会将需要发送的数据发送到缓冲区,等待缓冲区满了之后,再将缓冲中的数据发送到接收方。同理,接收方也有缓冲区这样的机制,来接收数据。
发生 TCP 粘包、拆包主要是由于下面一些原因:
- 应用程序写入的数据大于套接字缓冲区大小,这将会发生拆包。
- 应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包。
- 进行 mss(最大报文长度)大小的 TCP 分段,当 TCP 报文长度 - TCP 头部长度 > mss 的时候将发生拆包。
- 接收方法不及时读取套接字缓冲区数据,这将发生粘包。
如何解决拆包粘包
既然TCP 是无界的数据流,且协议本身无法避免粘包,拆包的发生,那么只能在应用层数据协议上加以控制。通常在制定传输数据时,可以使用如下方法:
- 使用带消息头的协议、消息头存储消息开始标识及消息长度信息,服务端获取消息头的时候解析出消息长度,然后向后读取该长度的内容。
- 设置定长消息,服务端每次读取既定长度的内容作为一条完整消息。
- 设置消息边界,服务端从网络流中按消息编辑分离出消息内容。
a)先基于第三种方法,假设区分数据边界的标识为换行符 “\n”(注意请求数据本身内部不能包含换行符),数据格式为 Json,例如下面是一个符合这个规则的请求包。
1 | {"type":"message","content":"hello"}\n |
注意上面的请求数据末尾有一个换行字符,代表一个请求的结束。
b)基于第一种方法,可以制定,首部固定 10 个字节长度用来保存整个数据包长度,位数不够则补 0 的数据协议
1 | 0000000036{"type":"message","content":"hello"} |
c)基于第一种方法,可以制定,首部 4 字节网络字节序 unsigned int,标记整个包的长度
1 | ****{"type":"message","content":"hello all"} |
其中首部四字节 * 号代表一个网络字节序的 unsigned int 数据,为不可见字符,紧接着是 Json 的数据格式的包体数据。
Netty对粘包和拆包问题的处理
Netty 对解决粘包和拆包的方案做了抽象,提供了一些解码器(Decoder)来解决粘包和拆包的问题。如:
- LineBasedFrameDecoder:以行为单位进行数据包的解码;
- DelimiterBasedFrameDecoder:以特殊的符号作为分隔来进行数据包的解码;
- FixedLengthFrameDecoder:以固定长度进行数据包的解码;
- LenghtFieldBasedFrameDecode:适用于消息头包含消息长度的协议(最常用);
基于 Netty 进行网络读写的程序,可以直接使用这些 Decoder 来完成数据包的解码。对于高并发、大流量的系统来说,每个数据包都不应该传输多余的数据(所以补齐的方式不可取),LenghtFieldBasedFrameDecode 更适合这样的场景。
小结
TCP 协议粘包拆包问题是因为 TCP 协议数据传输是基于字节流的,它不包含消息、数据包等概念,需要应用层协议自己设计消息的边界,即消息帧(Message Framing)。如果应用层协议没有使用基于长度、终结符信息或者消息边界等方式进行处理,则会导致多个消息的粘包和拆包。
